
Lee un resumen con IA
En el competitivo mundo del SEO, contar con las herramientas adecuadas puede marcar la diferencia entre el éxito y el estancamiento de una campaña de marketing digital. Entre las disponibles, Screaming Frog SEO Spider se destaca como una opción indispensable para entusiastas y profesionales del SEO. Se trata de una herramienta paga que, en su versión gratuita, permite analizar hasta un máximo de 500 URL.
En este artículo, te voy a explicar en profundidad las bondades de esta poderosa herramienta que permite escanear y auditar sitios web de manera eficiente, brindando información valiosa para la optimización de motores de búsqueda y el enfoque de las estrategias de Marketing Digital.
En el ranking de herramientas que más utilizo día a día para trabajar con nuestros clientes en nuestra Agencia SEO, el Screaming Frog SEO Spider se ubica en uno de los primeros lugares. Sabemos que Google cuenta con un algoritmo muy sofisticado, que se apoya en diversos factores de posicionamiento On Page y Off Page.
Screaming Frog permite “simular” cómo ve el robot de Google los factores On Page y tener una idea de qué está recibiendo su crawler para identificar puntos de mejora en las meta etiquetas Title, Descriptions, Canonicals, Cabeceras H1/H2, meta robots index/no index, URLs, páginas duplicadas, códigos de conversión, texto alternativo en imágenes, velocidad de carga y más. Para ello se le ingresa una página web de origen (por lo general el dominio principal de nuestro sitio) y a partir de ahí el software comienza a escanear recursivamente todas las páginas internas que detecta con cada hipervínculo encontrado.

¿Qué es Screaming Frog SEO Spider Tool?
Screaming Frog es una aplicación de software utilizada en el ámbito del marketing digital y el SEO. Esta herramienta está diseñada para rastrear y analizar sitios web de manera exhaustiva, proporcionando información detallada sobre diversos aspectos relacionados con el SEO.
A título personal, considero que esta es posiblemente la herramienta del SEO On Page por excelencia. Es cómoda y simple de utilizar, con una interfaz que creo es lo suficientemente intuitiva como para no perderse de ningún proceso.
¿Para qué sirve Screaming Frog y cuáles son sus ventajas para el SEO?
Screaming Frog cuenta con múltiples posibilidades de usos y ventajas dentro del área del SEO, entre las cuales es posible destacar:
- Auditoría de SEO Integral: Screaming Frog te permitirá realizar auditorías completas de los sitios web, identificando problemas y áreas de mejora relacionadas con metaetiquetas, encabezados, enlaces rotos, páginas duplicadas, meta robots, y otros aspectos esenciales para la optimización SEO.
- Identificación de errores: podrás detectar enlaces rotos, redirecciones incorrectas u otros problemas técnicos que pueden afectar la visibilidad en los motores de búsqueda.
- Análisis de velocidad de carga: si bien existen herramientas como PageSpeed Insights o GTmetrix, Screaming Frog también evalúa el tiempo de carga de las páginas, lo que es fundamental para la experiencia del usuario y el ranking en los motores de búsqueda.
- Auditoría de enlaces: es posible analizar la estructura de enlaces internos y externos, lo que contribuye a una mejor navegación y en la mejora de la autoridad del sitio.
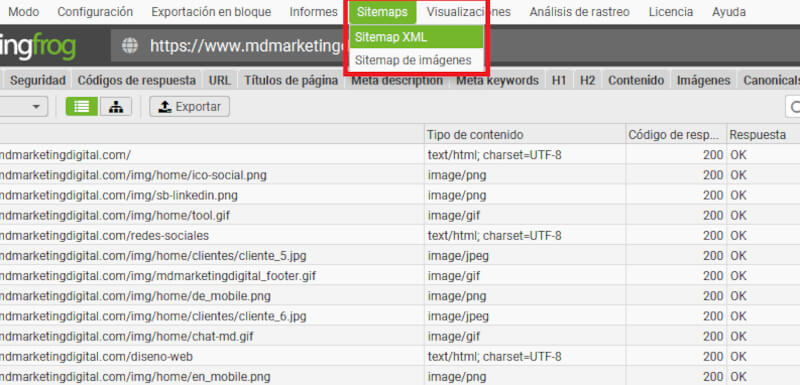
- Generación de sitemaps: se facilita la creación de mapas de sitio XML, mejorando la indexación de los motores de búsqueda de Google, Bing u otros más.
- Análisis de Competidores: esta herramienta resulta útil para analizar la competencia y comparar elementos clave, lo que ayuda a identificar oportunidades y estrategias efectivas.
¿Aún necesitas más pruebas para considerar a Screaming Frog una herramienta única y necesaria para la labor del SEO? Continúa leyendo para comprender en profundidad las funciones útiles que puede proporcionarte este software.
Funciones útiles de Screaming Frog
A lo largo de mi tiempo como SEO, Screaming Frog me ha permitido analizar sitios web de manera exhaustiva mediante múltiples funciones que resultan ser verdaderamente útiles. Entre las más destacables, es importante mencionar:
Componentes del tablero de trabajo
Algunos de los componentes que integran el tablero de trabajo de Screaming Frog son:
- Interfaz principal: al abrir Screaming Frog, te encontrarás con una interfaz limpia y simple para configurar tus análisis.
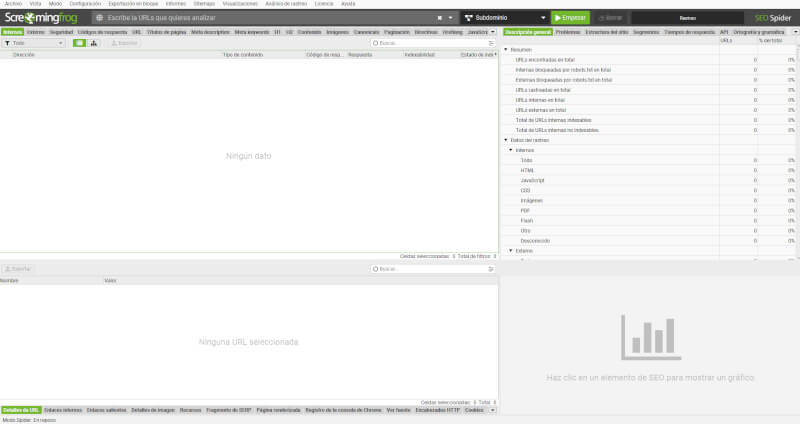
- Menú de configuración: aquí es donde puedes definir parámetros como la URL del sitio a analizar, la profundidad del rastreo y las restricciones de tiempo, entre otros aspectos relevantes para el SEO.
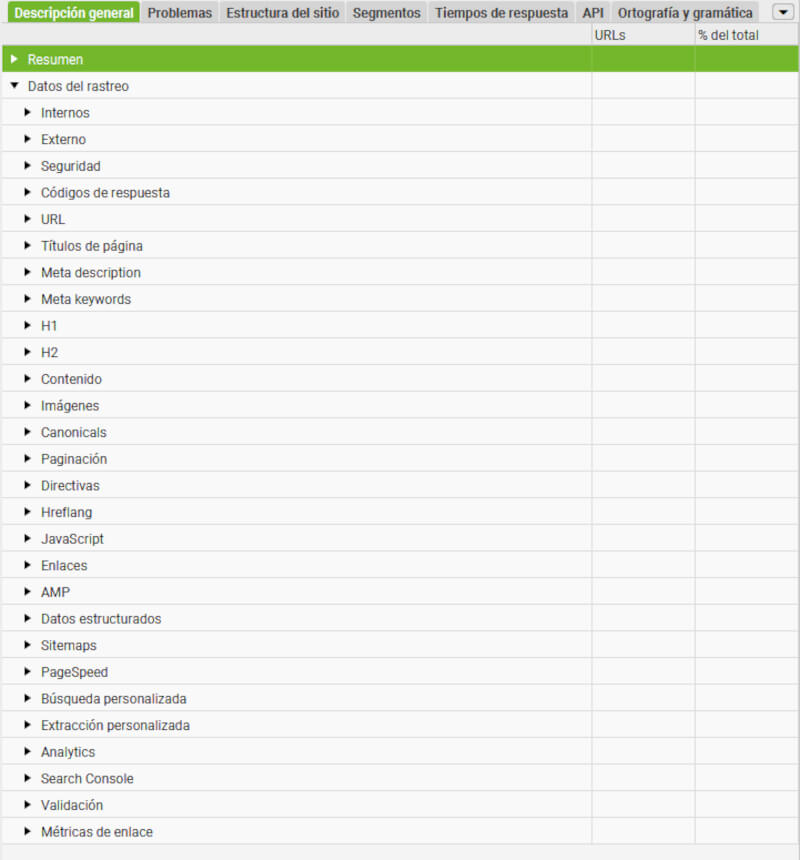
- Información del proyecto: esta herramienta almacena datos de análisis previos, lo que facilita la comparación de los resultados finales.
- Vista de datos: este software te proporciona información detallada sobre diversos aspectos del sitio web, incluyendo enlaces rotos, metadatos, códigos de respuesta y más.
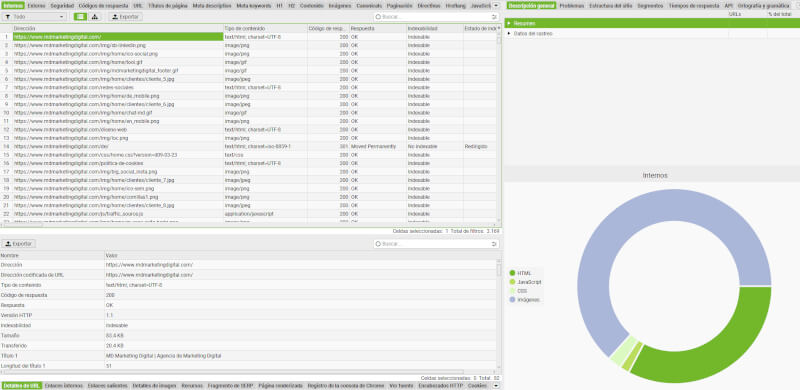
Funciones importantes
Puedo confirmar que, para el trabajo de un SEO, existen funciones importantes que pueden facilitar y agilizar dicho proceso. Algunas de las más importantes son:
- Crawl Website: esta función se encarga de escanear todo el sitio web en busca de información relevante para poder realizar la auditoría.
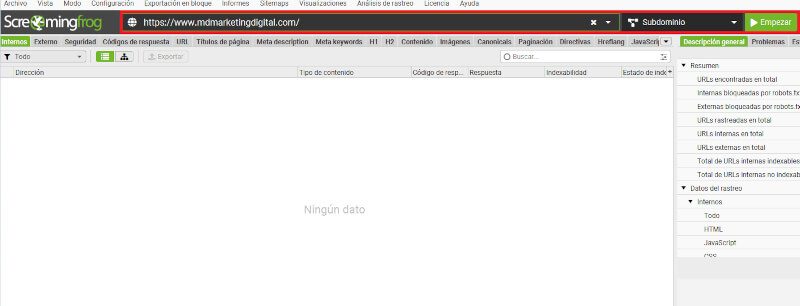
- Auditoría SEO: identifica errores de SEO, como enlaces rotos y etiquetas meta duplicadas.
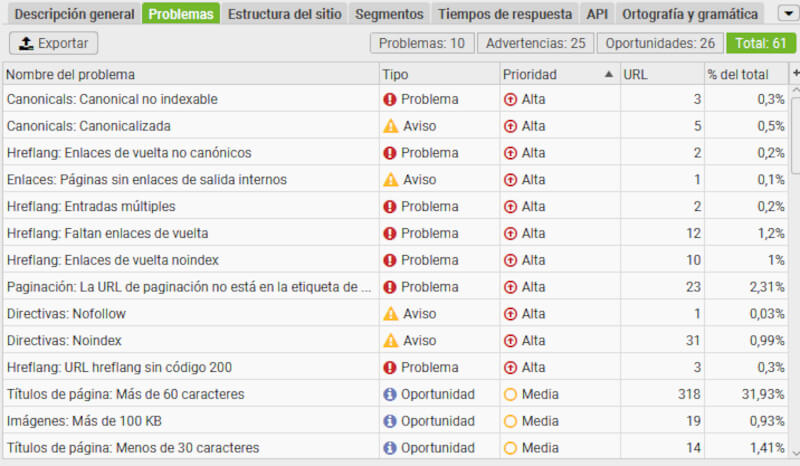
- Extracción de datos: sirve para recopilar datos como títulos, metadescripciones y encabezados.
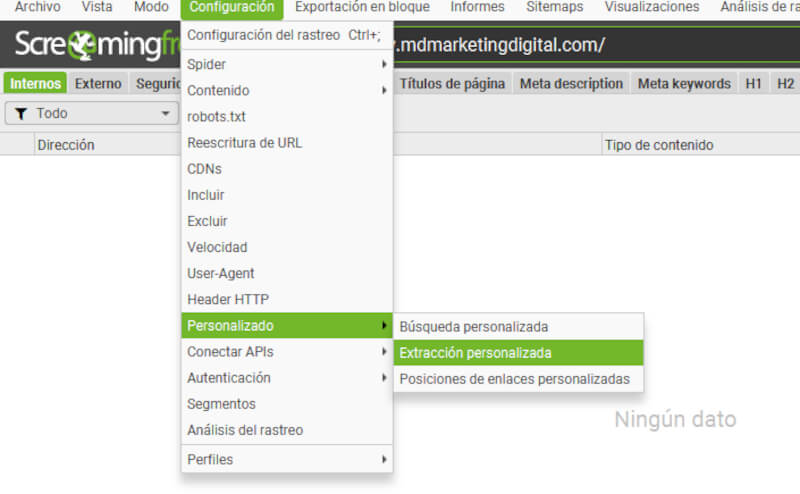
- Análisis de enlaces: esta herramienta de Screaming Frog muestra información sobre enlaces internos y externos dentro de un determinado sitio web.
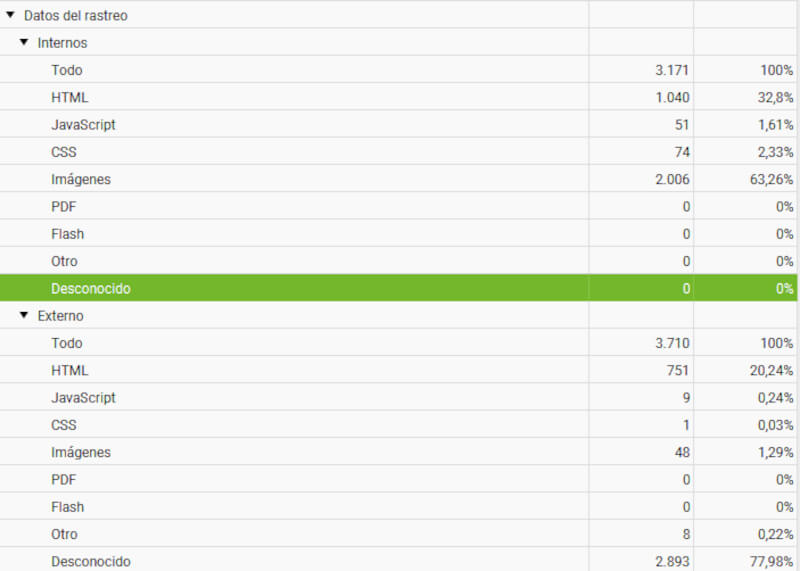
- Generación de sitemaps: se puede crear sitemaps XML para mejorar la indexación.
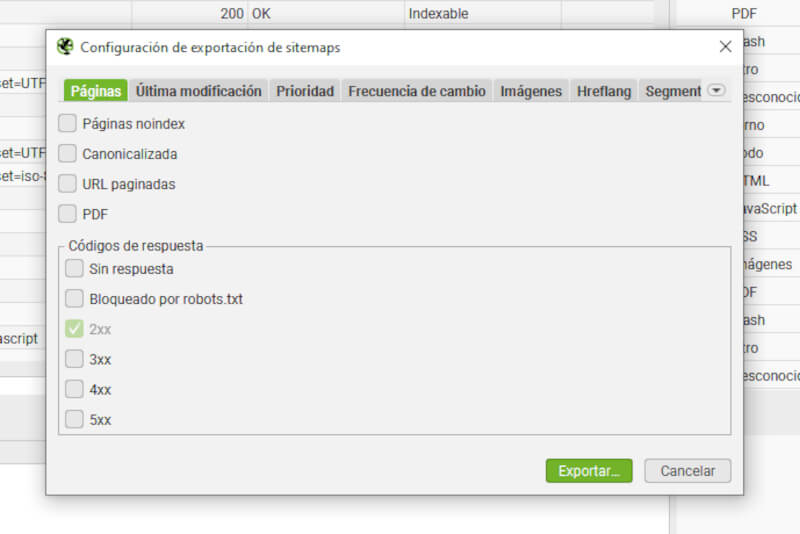
- Integración con Google Analytics y Search Console: es posible conectar tus cuentas de Google para un análisis más profundo (esto te lo explicaré más adelante en la sección de APIs).
¿Cómo usar Screaming Frog? Guía completa de la herramienta en español
A continuación, te compartiré algunos aspectos relacionados con el uso de la herramienta Screaming Frog:
Configuración de SEO Spider de forma convencional
Entiendo que, para poder emplear correctamente esta herramienta, es necesario instalarla de forma convencional. Por eso mismo, a continuación, te compartiré los pasos para lograrlo:
- Descarga e instala Screaming Frog SEO Spider desde el sitio oficial.
- Abre la herramienta y selecciona “File” en la parte superior izquierda.
- Haz clic en “Configuration” para ajustar las opciones de rastreo.
- Debes configurar las opciones según tus necesidades. Puedes personalizar la velocidad de rastreo, los límites, las reglas de extracción y más.
- Una vez configurado, presiona “Start” para iniciar el rastreo. La herramienta analizará el sitio web y mostrará los resultados.
¿Cómo configurar Screaming Frog SEO Spider Tool para JavaScript?
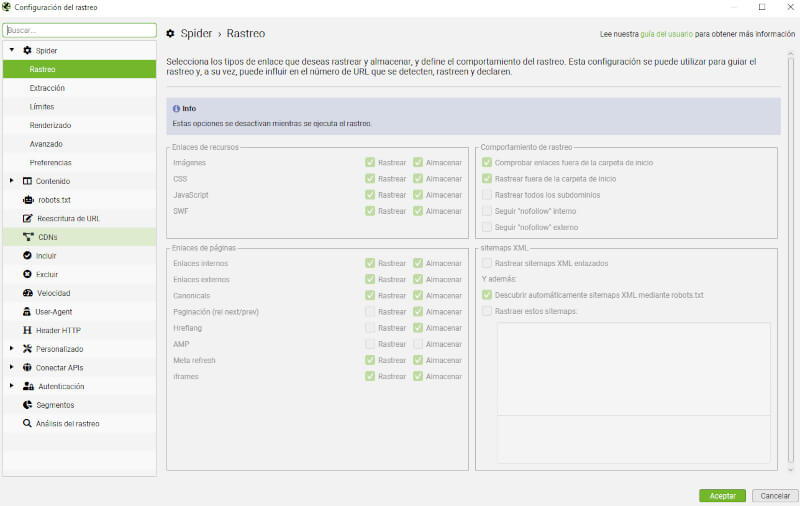
En el caso de que quieras configurar la herramienta para utilizar con JavaScript, te recomiendo seguir muy de cerca los siguientes pasos que te compartiré:
- Debes ir a “Configuración” > “Spider” > “Rastreo”.
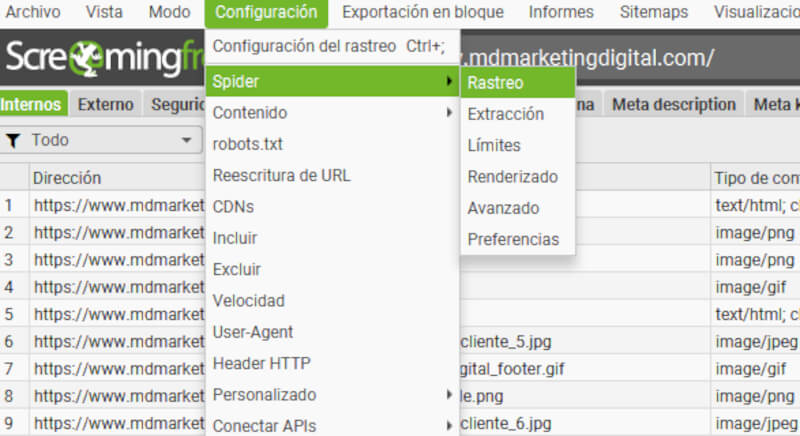
- Habilita las opciones “Rastrear” y “Almacenar” para permitir que la herramienta rastree contenido generado por JavaScript de tu sitio web.
- Puedes configurar otras opciones de renderizado según tus necesidades.
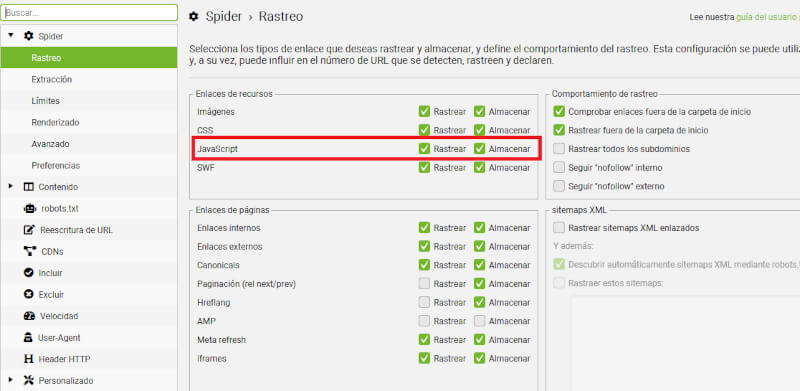
Configurar Screaming Frog para JavaScript me ha servido para analizar correctamente sitios web que utilizan JS para cargar sus contenidos, o bien que hayan sido programados con dicho lenguaje. Esta función es especialmente útil si necesitas saber si tu sitio se ha indexado correctamente y si los motores de búsqueda logran acceder correctamente al contenido.
¿Cómo exportar la información desde Screaming Frog y cuáles son las columnas más importantes para una auditoría SEO básica?
Una vez que la herramienta hizo su rastreo de un sitio web, lo que suelo hacer es exportar la información a otro documento, ya sea en formato .csv o .xlsx. Sin dudas, mi recomendación es exportarlo a un drive de hojas de cálculo, para que tu información se mantenga siempre en la nube y sin riesgos de perderse.
A continuación, te comparto los procedimientos que debes realizar para poder exportar correctamente los datos de tu auditoría:
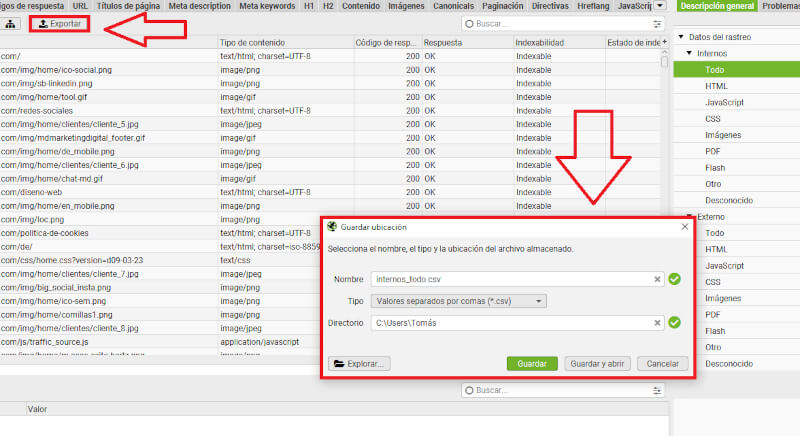
- Una vez completado el rastreo, debes dirigirte al botón “Exportar”.
- Selecciona el tipo de exportación: puedes optar por exportar datos como un archivo CSV, Excel o Google Sheets.
- Finalmente, debes hacer clic en la opción “Exportar” seleccionando el formato que desees y guardar tus datos.
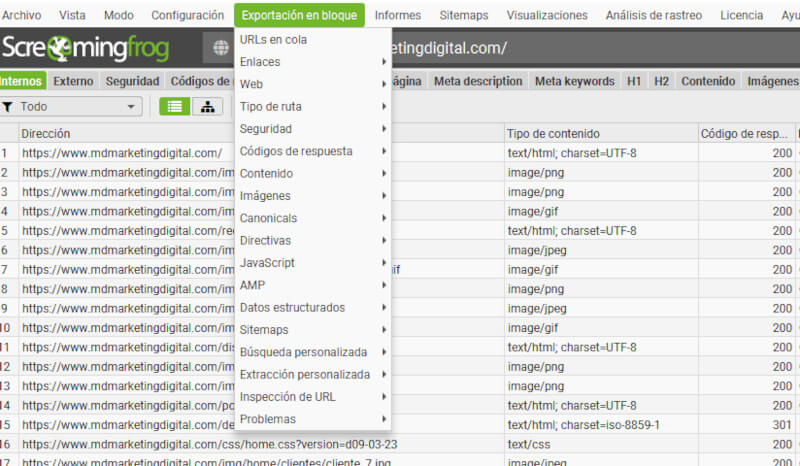
- Si quieres exportar por bloque, es posible hacerlo dirigiéndote a “Exportación en bloque” y elegir lo que desees exportar.
En el caso de necesitar realizar una auditoría SEO básica, los aspectos más relevantes a considerar siempre serán:
- URL.
- Título de la página (Title).
- Meta descripción (Meta description).
- H1 (es el encabezado principal del artículo).
- Código de estado (Status Code).
- El recuento de palabras.
- Imágenes.
- Atributo ALT de las imágenes.
- Enlaces entrantes.
- Enlaces externos.
Seguramente te estarás preguntando la real importancia de estos elementos de una página o sitio web. No es exagerado decir que todos son igualmente importantes, ya que constituyen la estructura de un sitio web y sus entradas.
Estos aspectos deben ser revisados constantemente, ya que los Update de Google son frecuentes, además de la importancia de las actualizaciones de Helpful Content (contenido útil).
Uso avanzado de Screaming Frog en Español: conexión con distintas APIs
Una API, o Interfaz de Programación de Aplicaciones, es un conjunto de reglas que permiten que una aplicación externa se comunique con otros servicios y obtenga datos de ellos. En el contexto de Screaming Frog, esto significa que puedes vincular la herramienta con diversas APIs para enriquecer tu análisis SEO.
A lo largo de mi experiencia con este software usé muchas APIs, como lo son Google Analytics, Google Search Console, Moz, Majestic, Ahrefs y muchos otros más. Con estas integraciones, podrás recopilar datos adicionales para mejorar tu auditoría SEO.
Para conectar Screaming Frog a una API, te recomiendo seguir estos pasos:
- Abre Screaming Frog y ve a “Configuration” en el menú superior.
- En la sección “API Access” selecciona la API que deseas utilizar.
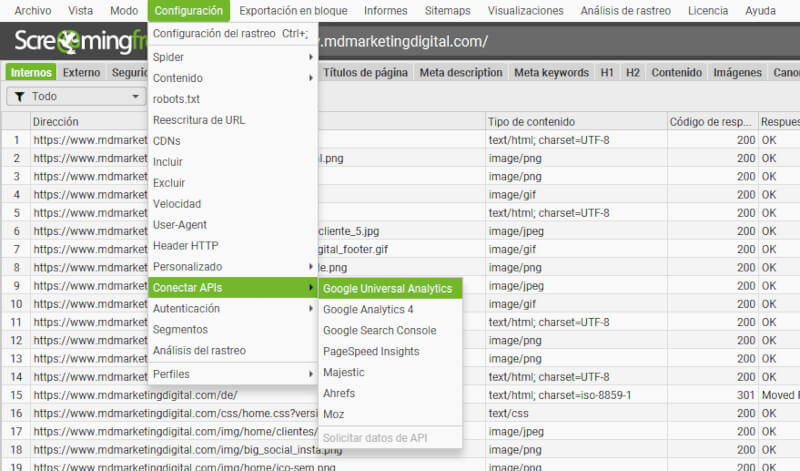
- Luego, debes ingresar las credenciales requeridas para la API en cuestión.
- Asegúrate de activar la casilla de verificación para habilitar la API.
- Guarda la configuración y ejecuta un nuevo rastreo. Screaming Frog se conectará a la API y recopilará datos adicionales.
Screaming Frog es la herramienta definitiva para el SEO on-page
En conclusión, me es posible confirmar que Screaming Frog es una herramienta específica y dirigida para los profesionales del SEO. Gracias a sus facilidades, es posible auditar todo tipo de sitios web de manera exhaustiva, identificando errores, conectándose a distintos tipos de APIs y analizando la velocidad de carga. Sin dudas, una de las herramientas más confiables para llevar a cabo auditorias on-page de una página web.
Si buscas mejorar tu sitio web y no logras encontrar la forma, no te preocupes, en MD Marketing Digital contamos con un equipo de profesionales especialistas en SEO y en todas las áreas del Marketing. Podemos auditar tu sitio y encontrar sus puntos débiles, para, posteriormente, realizar las optimizaciones adecuadas y ayudarte a posicionarlo de manera orgánica.
¡No dudes en contactarnos para impulsar el posicionamiento de tu sitio y aumentar sus visitas!
¿Aún te quedan dudas?
Si aún tienes dudas o te quedaste con ganas de saber un poco más sobre esta indispensable herramienta SEO, te invitamos a que veas los siguientes videos de #MDEnseña:

- Tendencias en marketing digital: historia y evolución - diciembre 12, 2025
- El Ranking de mejores agencias de Marketing Digital de México - febrero 7, 2025
- ¿Cómo crear una estrategia SEO efectiva en 2025? - noviembre 8, 2024
¿Qué te pareció este artículo?
What do you think about this post?


